今天,阿里巴巴通义千问团队扔出了一枚"重磅炸弹"——正式推出仅320亿参数的QwQ-32B大语言模型。这个看似中等体量的模型,竟在多项关键指标上追平甚至超越了顶尖模型DeepSeek-R1。

从官方披露的数据来看,QwQ-32B的突破主要源于强化学习技术的创新应用。研发团队摒弃了传统奖励模型,转而通过分阶段训练策略:先用数学题答案验证和代码测试执行结果作为反馈,夯实基础推理能力;再引入通用奖励模型扩展综合实力。这种"精准投喂"的**方式,让模型在参数量仅为对手1/21的情况下,不仅保住了性能基准线,还把推理成本压缩到十分之一。有网友实测发现,该模型在笔记本电脑上就能流畅运行,思考过程还能实时可视化,这性价比直接拉满。
在权威评测中,QwQ-32B展现出了"以小搏大"的硬实力。面对被称为"LLM终极考场"的LiveBench榜单,它不仅以72.5分反超DeepSeek-R1的70分,更以0.25美元的成本远低于对手2.5美元的推理开销。在代码生成、数学解题等专项测试中,其表现甚至优于部分专门优化的蒸馏模型。最令人惊喜的是,它还能像人类一样在使用工具时进行"自我纠错",根据环境反馈动态调整推理路径。
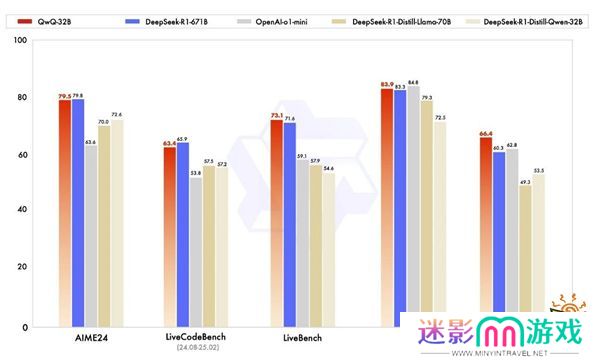
这波操作背后的技术路径确实让人眼前一亮。当行业还在为"万亿参数俱乐部"的门槛争得头破血流时,阿里选择用强化学习深挖模型潜力,某种程度上打破了"参数即正义"的固有认知。正如业内人士评价,这种中等规模模型的高效表现,既为开源社区提供了新思路,也降低了企业部署AI的门槛。
目前该模型已在Hugging Face和ModelScope双平台开源,普通用户通过Qwen Chat就能直接体验。